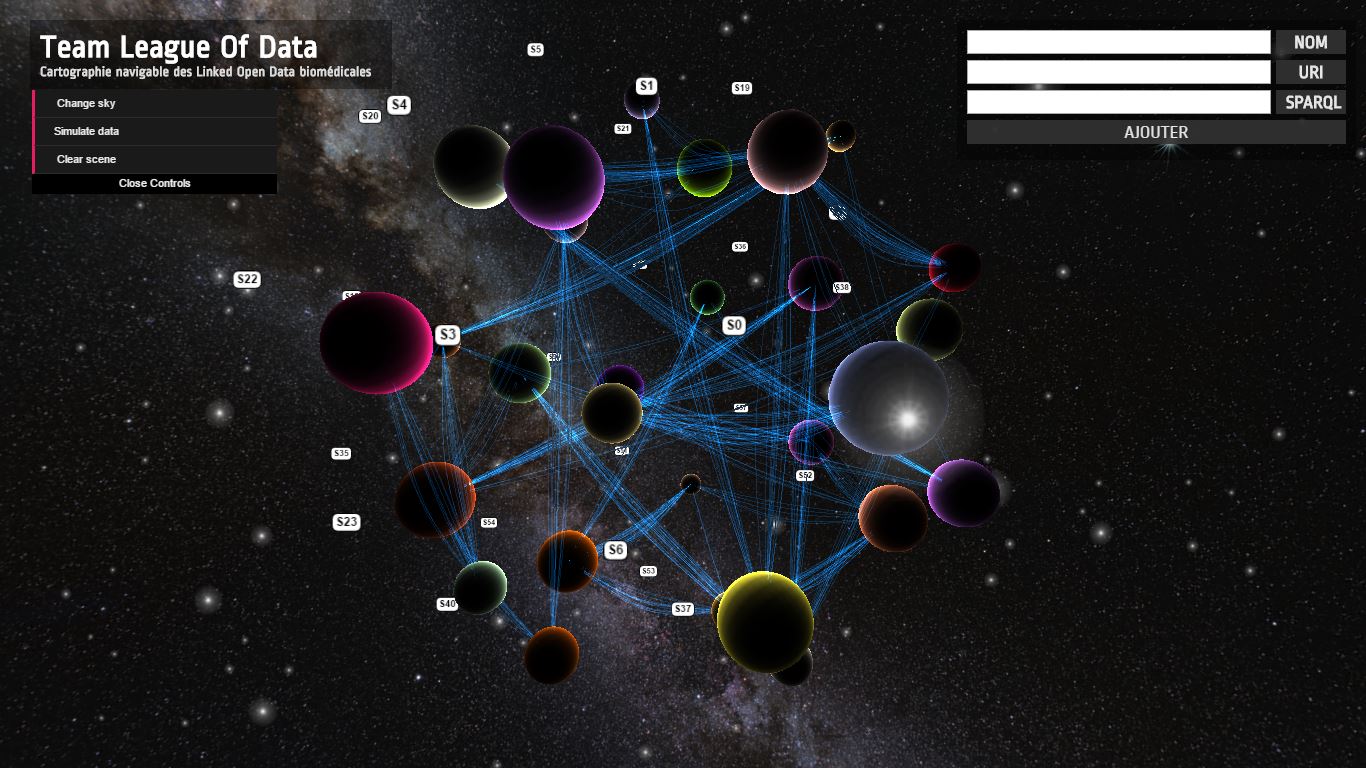
Sujet 1 : MYRISSI
MYRISSI, startup nancéenne, a développé le 1er traducteur sensoriel, un assistant marketing basé sur des algorithmes d’Intelligence Artificielle, qui permet de naviguer à travers 3 espaces sensoriels : la vue et plus spécifiquement les couleurs, l’olfaction avec les odeurs et les parfums et enfin l’émotion, composante indissociable de toute réponse sensorielle.
MYRISSI propose une boite à outils permettant de traduire tous types d’odeurs ou parfums en couleurs et émotions et inversement, et ainsi de maximiser l’adéquation entre les développements de produits olfactifs d’un côté, et les attentes des consommateurs de l’autre. Appliquées à la relation BtoC, les technologies de Myrissi permettent de prédire scientifiquement la concordance entre une personnalité, une envie et un produit.
Dans le cadre de sa participation au CES de Las Vegas, MYRISSI a développé un fragrance finder permettant de trouver un parfum en fonction de sa personnalité et de ses envies. Ce fragrance finder est accessible ici
Ce fragrance finder fonctionne sur une base de données affectives contenant 78 items et 24 couleurs.
L’objectif de ce projet est de développer un chatbot intégrant une IA (ou une association de technologies existantes open source) permettant de sélectionner dans cette base affective de 78 items, les émotions, les traits de personnalité d’un consommateur à partir d’une phrase qu’il aurait écrite en langage naturel. Ce chatbot doit permettre à terme d’intégrer en plus les algorithmes de MYRISSI permettant de lier émotions, couleurs et parfums.
Pour résumer, actuellement, le fragrance finder de MYRISSI fonctionne avec 4 questions :
- Est-ce un parfum pour homme, femme ou mixte ?
- Quelles émotions doit véhiculer ce parfum ?
- Quels traits de personnalité doit-il exprimer ?
- Quelles sont vos couleurs préférées ?
Le nouveau chatbot devra dans l’idéal se substituer aux questions 1 à 3 et a minima aux questions 2 et 3 et permettre à l’utilisateur de se décrire, de raconter son histoire simplement avec ses mots et in fine le conduire vers le parfum qui lui conviendrait le mieux.
Contact : Muriel JACQUOT, MYRISSI, Muriel.jacquot@myrissi.fr











 Team Felicity
Team Felicity