


Parcours d'internautes sur les sites d'ONG
Hackathon Telecom Nancy 2015
Durant une semaine, nous avons dû développer une solution correspondant
à un problème donné par une entreprise. Nous avons eu la possibilité de travailler
avec iRaiser, une start-up basée à Nantes, éditrice de logiciels pour des ONG.
Présentation du projet
iRaiser capture des données anonymes sur les internautes visitant les pages de certaines ONG dans l'objectif de mieux comprendre le comportement des donateurs et ainsi proposer des améliorations de ces sites web. Pour le Hackathon, un échantillon de données portant sur 6 mois a été constitué.
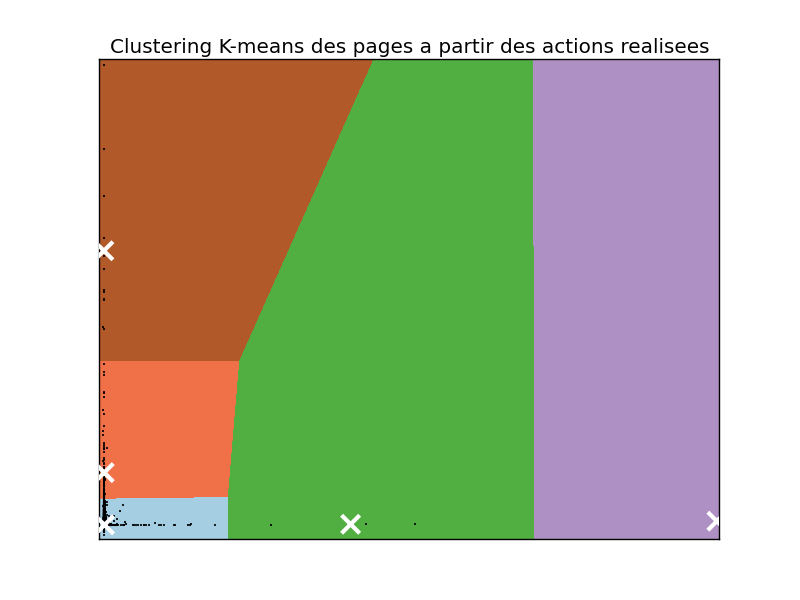
Clustering des pages
Le site compte des dizaines de milliers de pages, ce qui rend cette information peu exploitable en l'état. Les regrouper en nombre restreint de catégories permettrait de mieux comprendre le comportement de l'internaute. Comme on ne peut pas se baser sur le contenu des pages, on s'intéresse aux parcours des internautes en supposant qu'ils naviguent sur des pages de contenu similaire.
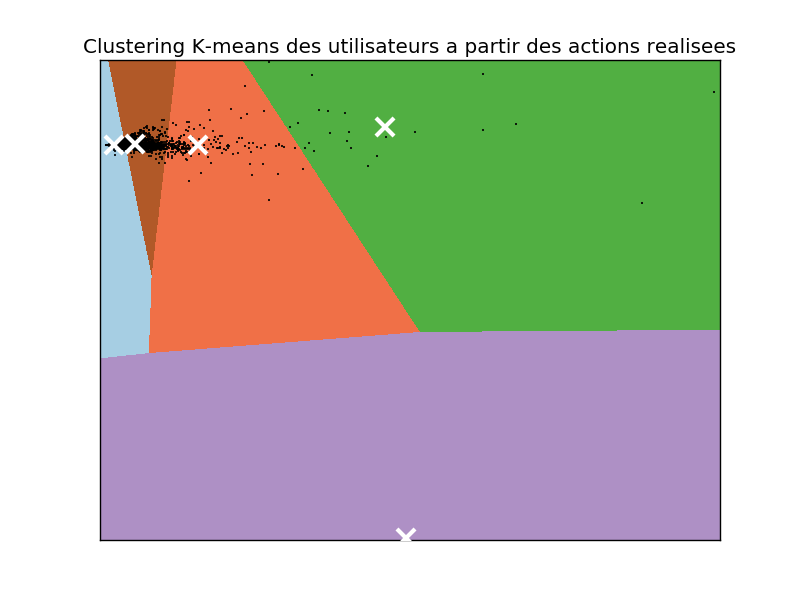
Clustering des utilisateurs
Ici, on se concentre sur le parcours des internautes. On veut regrouper les utilisateurs en
catégories similaires, puis mesurer sur chaque catégorie la propension à donner ou
simplement visiter le formulaire de don pour pouvoir ensuite faire du marketing ciblé.
Des utilisateurs similaires ont des parcours de navigation semblable.
Clustering sur les données des
utilisateurs sans modification.

Groupement des utilisateurs en catégories
suivant s'ils regardent des vidéos, du texte,
des images, des cartes ou des schémas.
A partir des clusters obtenus, nous avons calculé des statistiques sur
le pourcentage de don et le pourcentage d'entrées sur le formulaire.
Résultat : 17% des utilisateurs appartenant au plus gros cluster
cliquent sur la page du formulaire et 2% font effectivement un don.
Prédiction des dons
Nous avons essayé de prédire l'action de faire un don en mettant en place des catégories d'utilisateurs.
Pour faire cela nous avons utilisé des algorithmes de classification que nous avons comparés.
Découpage des utilisateurs en trois classes :
don sans en faire un
Utilisation de trois algorithmes :
Qui sommes-nous ?
Nous sommes une équipe de 4 étudiants de Telecom Nancy, une école d'ingénieur en informatique et sciences du numérique. Nous sommes spécialisés dans le domaine du Big Data et du Data Mining.